Claude Fable 5 完全ガイド ― 何が強く、何がブロックされ、いくらかかるのか
AnthropicがOpus 4.8からわずか13日で投入した「Mythos級を一般開放した」モデル、Claude Fable 5。ベンチマーク15項目・Stripeの5000万行移行事例・3つの内蔵分類器という安全設計・料金とアクセス方法まで、発表資料を一次ソースから整理した保存版。編集部は実際に検証動画3本ぶんのテストを実施済み。
3行まとめ
- Fable 5は「Mythos級の頭脳に安全装置を付けて一般開放した」モデル。コーディング・長時間の自律タスク・空間推論でOpus 4.8とGPT-5.5を広く上回る
- 安全設計が構造的に変わった。拒否ではなく、危険な話題だけOpus 4.8に切り替わるフォールバック方式(発動は平均5%未満のセッション)
- API価格は入力$10/出力$50(100万トークンあたり)でOpusの2倍。ただし段階展開中はPro/Maxプランで追加料金なし。claude.aiのモデル選択から今すぐ使える
何が出たのか ― Fable 5とMythos 5は二卵性双生児
Anthropicは2026年6月9日、「Claude Fable 5」と「Claude Mythos 5」を同時発表した。Opus 4.8のリリースからわずか13日後の投入である。
2つのモデルの中身は同じだ。違いは安全装置だけ。
- Fable 5: 一般ユーザーが使える方。サイバー攻撃・生物化学兵器・蒸留(他社AIによる回答の大量収集)を検知する3つの分類器を内蔵し、該当する話題ではOpus 4.8に処理を切り替える
- Mythos 5: 正規のサイバーセキュリティ研究機関など向けに、一部の安全装置を外した方。米政府と連携した招待制プログラム「Project Glasswing」限定で提供される
つまり一般人が触れる「Anthropic史上最高性能のモデル」はFable 5ということになる。
ベンチマーク ― どこが強いのか
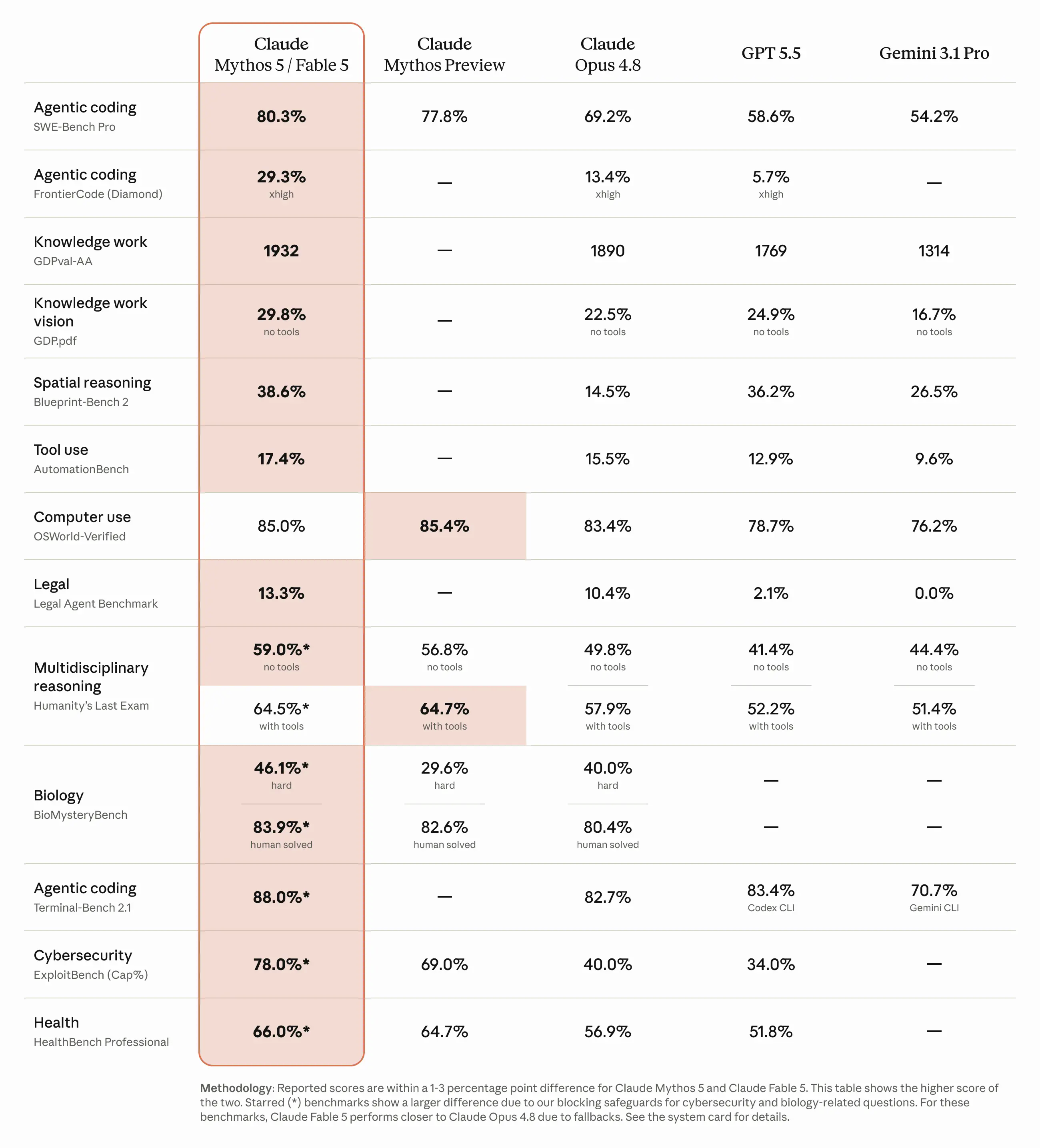
公式発表のベンチマークから、差が大きかった項目を抜粋する(いずれもAnthropic公表値。比較対象はOpus 4.8 / GPT-5.5 / Gemini 3.1 Pro)。
| 領域 | ベンチマーク | Fable 5 | 比較 |
|---|---|---|---|
| 実コード修正 | SWE-Bench Pro | 80.3% | GPT-5.5(58.6%)に21pt差 |
| 難関コーディング | FrontierCode Diamond | 29.3% | GPT-5.5(5.7%)の5倍超 |
| ターミナル自律操作 | Terminal-Bench 2.1 | 88.0% | Codex CLI(83.4%)を逆転 |
| PC自律操作 | Computer use | 85.0% | GPT-5.5(78.7%)+6pt |
| 空間推論 | Blueprint-Bench 2 | 38.6% | Opus 4.8(14.5%)の2.6倍 |
| 法律エージェント | Legal Agent | 13.3% | GPT-5.5(2.1%)の6倍 |
| 医療 | HealthBench Professional | 66.0% | GPT-5.5は51.8% |
| 総合難問 | Humanity's Last Exam(ツールあり) | 64.5% | GPT-5.5は52.2% |
個別の数字より重要なのは傾向だ。公式発表は「タスクが長く複雑になるほど、他モデルとの差が開く」と説明しており、コストをかけた時の伸び方にもそれが現れている。
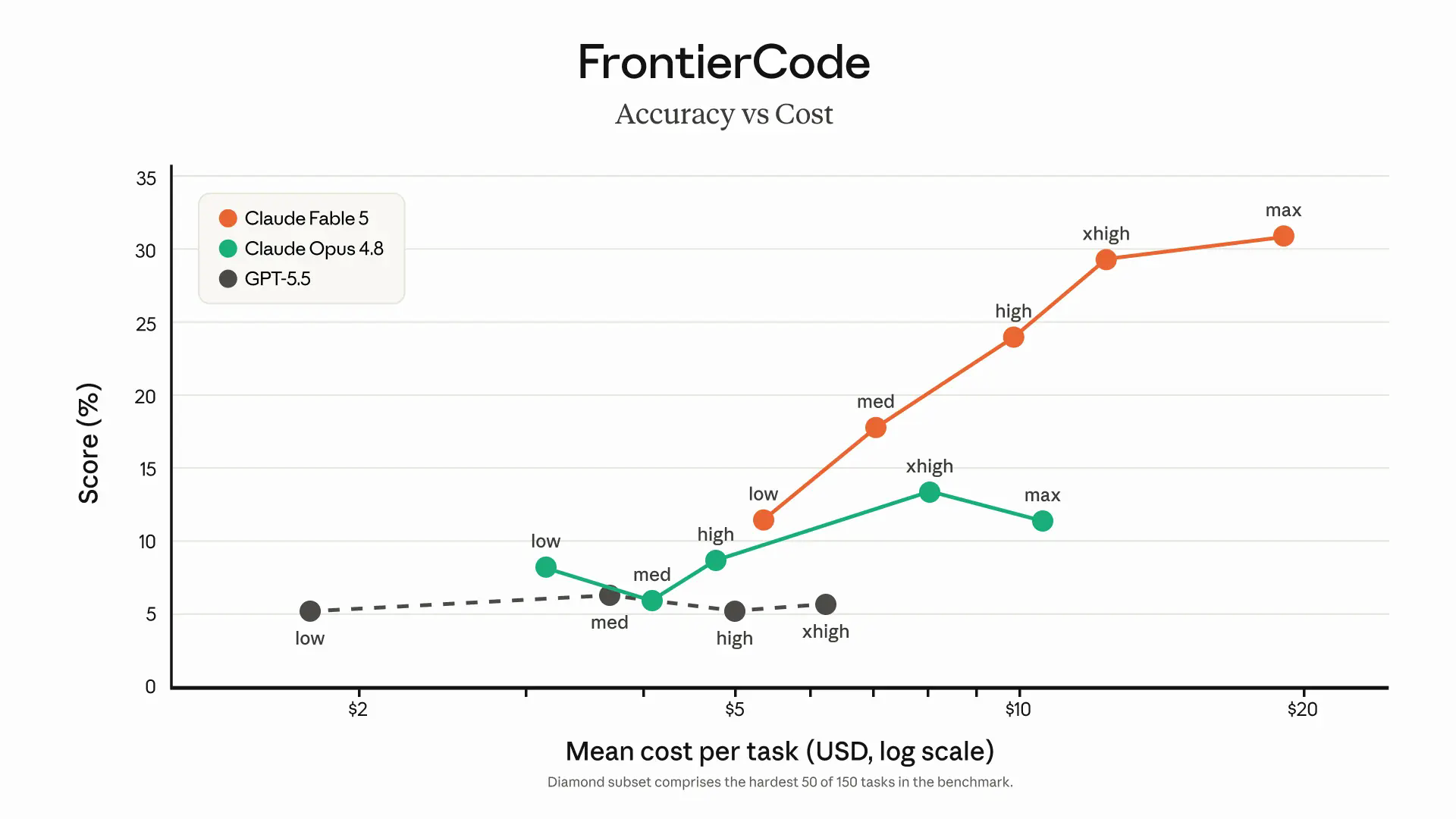
GPT-5.5はコストを増やしても精度がほぼ横ばい、Opus 4.8は途中で頭打ちになるのに対し、Fable 5だけがコストに比例して伸び続ける——「考えさせるほど強い」型のモデルだ。
実事例 ― Stripeの5000万行移行
ベンチマークより生々しいのが実事例だ。公式発表によれば、決済大手のStripeが5000万行のRubyコードベースを全面移行するのにFable 5を使い、「手作業ならチームで2ヶ月以上かかる作業を、わずか1日でやってのけた」という(原文: a codebase-wide migration in a day that would otherwise have taken a whole team over two months by hand)。
もうひとつ面白いのがゲームの事例で、カードゲーム「Slay the Spire」をファイルに記憶を書き込みながらプレイさせたところ、従来の3倍のスコアを出した。長期タスクで「自分用のメモを取りながら作業する」挙動は、実務の長時間エージェント運用にそのまま効く性質だ。
安全性 ― 「拒否するAI」から「切り替わるAI」へ
5シリーズで構造的に変わったのがここだ。
これまでの安全設計は「危険な依頼を拒否する」方式で、その副作用として普通の依頼まで断る過剰拒否が問題になってきた。Anthropicの公表値では、過剰拒否率はOpus 4.6の83.2%→4.7の72.7%→4.8の56.6%と徐々に改善してきたが、Fable 5では5.4%と一気に10分の1以下になった。
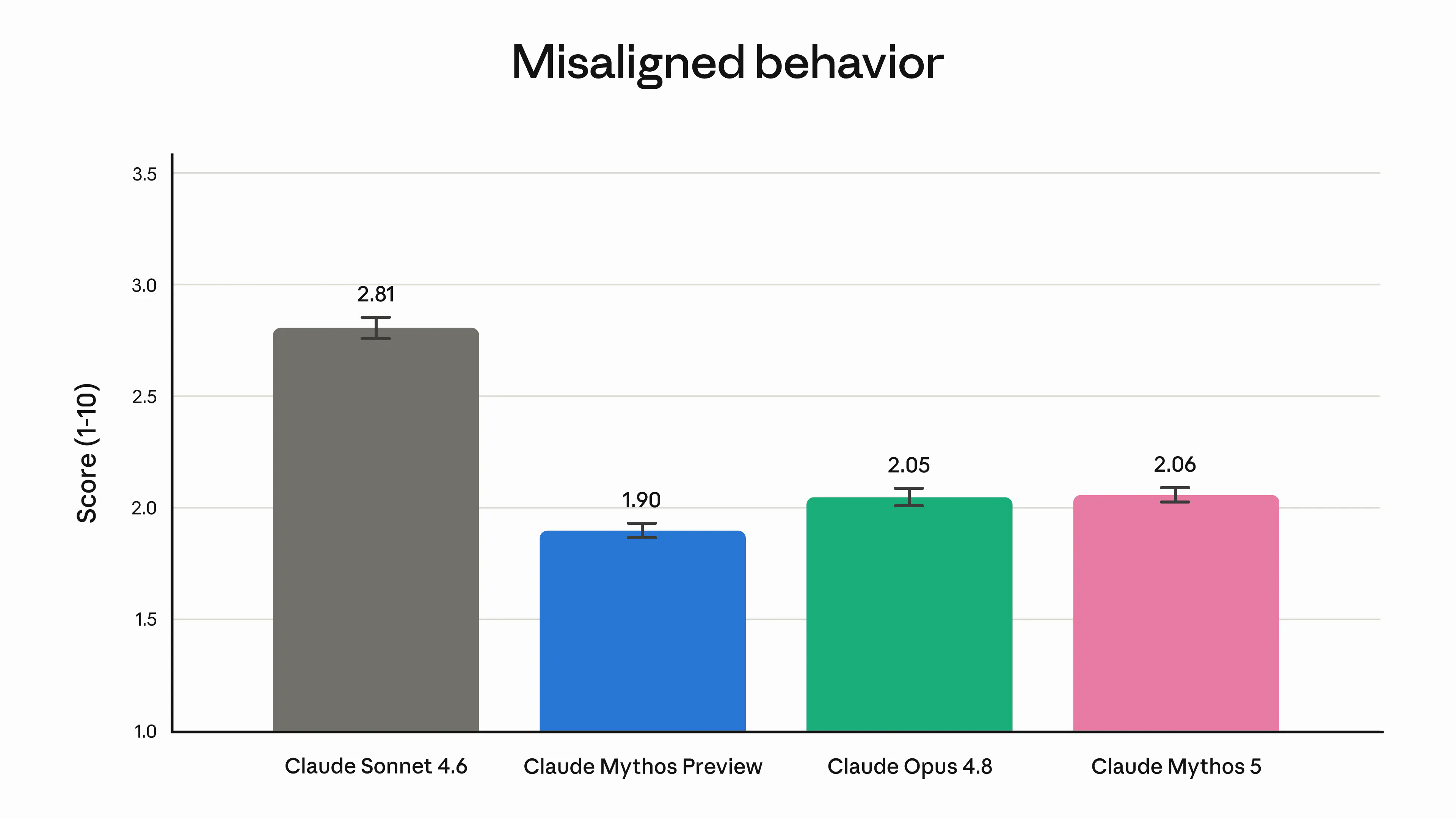
仕組みが違う。Fable 5は危険な話題を3つの内蔵分類器(サイバー攻撃/生物・化学/蒸留防止)で検知すると、拒否する代わりにOpus 4.8に切り替えて応答する。公式発表には「95%以上のセッションではフォールバックが一切発生しない」と明記されている。
実際、サイバー攻撃タスクの成功率テストでFable 5は全テストでゼロ(完全ブロック)。同じ中身のMythos 5はCyberGymで83.8%を出しており、安全装置の有無で全く別のモデルになることが分かる。
料金とアクセス

- API: 入力$10/出力$50(100万トークンあたり)。Opus 4.8の2倍だが、Mythosプレビュー比では50%以上の値下げ。モデルIDは
claude-fable-5 - claude.ai: 段階展開中はPro/Maxプランで追加料金なし。モデル選択で「Fable 5」を選ぶだけ
- ⚠️ 6月23日以降は使用クレジットの消費量が2倍になるとアナウンスされている(Coworkは7月5日まで2倍に拡大)。「実質無料期間」は期限付きだ
- データポリシー: Mythosクラスのトラフィック(Fable 5 / Mythos 5)には30日間の保持ポリシーが適用される
編集部の検証 ― 数字にならない変化
当ラボはリリース当日から実際にFable 5でテストを行い、検証動画を3本公開している。ベンチマークに出ない所感を2つだけ。
- 文字制御系のタスク(文字数指定・縦読み・リポグラム・回文)の比較テストでは、Fable 5はタスクの「意図」まで読む挙動を見せた。リポグラムのテスト中に「これは動画コンテンツになりますよ」とテストの目的自体を言い当ててきたのが象徴的だった
- 意図汲みの精度が体感で最も変わった。曖昧な依頼から先回りして成果物を作る挙動は、4.8までとは別物だと感じている(これは体感であり、定量評価ではない)
正直な注意点
- ベンチマークは全てAnthropic自社測定で、独立検証はこれから。発表直後の数字は変動・訂正がありうる
- 「Opus 4.8の2倍」のAPI価格は、軽いタスクには明確に過剰。使い分けが前提のモデルだ
- クレジット2倍化(6/23〜)以降のコスト感は要再計算。本記事の条件は執筆時点(2026年6月11日)のもの
まとめ ― 誰が乗り換えるべきか
- 長時間の自律タスク・大規模コード・エージェント運用をする人: 乗り換える価値が最も大きい。差が出るのはまさにこの領域
- 日常の軽い質問・下書きが中心の人: 急がなくていい。Pro/Maxの無料期間中に手元のタスクで試して、体感差があるかだけ確認しておくのが合理的
- 安全装置が業務に干渉しないか不安な人: フォールバック発動は平均5%未満。まず通常業務で発動するか試せばいい
当ラボの検証は動画でも公開している。続報・実測はこのサイトで追っていく。
検証環境: claude.ai Pro / 2026年6月9日〜実施。ベンチマーク数値はAnthropic公式発表の公表値、事例は同発表の記載にもとづく。
📎 出典・一次ソース
このニュースの解説動画も作っています
解説動画はYouTube、速報はX(旧Twitter)で毎日更新中。
毎日のAIニュース、追えていますか?
出典付きのまとめを不定期でお届けします。登録無料・いつでも解除。


